Lucy Havens (Digital Research Intern) spent July-September 2020 exploring some of the Data Foundry collections with Jupyter Notebooks.
This blog post first appeared on the Scottish Working Forum on Official Publications (SWOT) website
As a Digital Library Research Intern at the National Library of Scotland (NLS), I’ve contributed to several tools for digitally exploring NLS collections. On the Data Foundry website, the Library publishes its digitised collections and collections data, as well as tools for exploring that data. Prior to my internship, the Library had published tools for exploring its map collection and geospatial datasets. Now, its tools include Jupyter Notebooks for conducting text analysis. I created five Jupyter Notebooks for five collections on the Data Foundry which explore digitised text and metadata.
What is a Jupyter Notebook?
A Jupyter Notebook is an interactive document that can display text, images, code, and data visualisations. Jupyter Notebooks have become popular in data science work because they facilitate easy documentation of data cleaning, analysis, and exploration. Explanatory text can describe what code will do and comment on the significance of the results of code after it runs. Live code can create and display text, images, tables, and charts. The data on which code runs can be sourced from a file, a folder of multiple files, or from a URL (an online data source). Even if you don’t have the Jupyter Notebook software (which is free and open source!) downloaded to your computer, you can still interact with Jupyter Notebooks using MyBinder, which runs the Notebooks in an Internet browser.
Why use a Jupyter Notebook?
Jupyter Notebooks are useful for exploring collections as data, helping new research questions to be asked that complement close readings of text with distant readings. Using a coding language such as Python (which I used as Digital Research Intern), linguistic patterns such as word occurrences, and diversity of word choice can be measured across thousands of sentences in a matter of seconds. Thanks to the technical fields of computational linguistics and natural language processing, developers have created libraries of code that make it easy to reuse code that answer common questions in text analysis. One such library of code is Natural Language Toolkit, often referred to by its abbreviation, NLTK.
Jupyter Notebooks are useful for writing code to explore digitised collections because they support the Library’s collections data in achieving the FAIR data principles:
Findability – Jupyter Notebooks can be assigned a digital object identifier (DOI) to facilitate their findability. The Jupyter Notebooks on the NLS Data Foundry have DOIs and are also available on GitHub, a platform for creating and sharing open source coding tools.
Accessibility – As mentioned previously, a Jupyter Notebook is an open source software platform that anyone can download to their own computer, or that can be run in an Internet browser.
Interoperability – Jupyter Notebooks do not depend on a particular operating system or Internet browser (they can be run with Windows, macOS, Linux, etc.; and in Chrome, Firefox, Safari, etc). Furthermore, the Jupyter Notebooks on the NLS Data Foundry include links to their data sources (which are .TXT files on the Data Foundry). Every data source has licence information that provides guidance on how to use and cite the data.
Reuse – Jupyter Notebooks promote the reuse of the Library’s collections data because the Notebooks can be edited live in a browser, whether using MyBinder online or a local version of the software downloaded to your computer. You can edit both the explanatory text and code of a Jupyter Notebook, making it easier to write code even if you don’t have prior programming experience.
Exploring Britain and UK Handbooks in a Jupyter Notebook
One of the five collections I used as a data source during my time as Digital Library Research Intern is the Britain and UK Handbooks. The Handbooks dataset I used contains digitised text from official publications that report statistical information on Great Britain and the United Kingdom between 1954 and 2005. In the Exploring Britain and UK Handbooks Jupyter Notebook, I organise the data exploration process into four sections: Preparation, Data Cleaning and Standardisation, Summary Statistics, and Exploratory Analysis. The Notebook serves as both a tutorial for people who would like to write code to analyse digitised text, and a starting point for research on the Britain and UK Handbooks.
In Preparation, I load the files of digitised Britain and UK Handbooks available on the Data Foundry’s website.
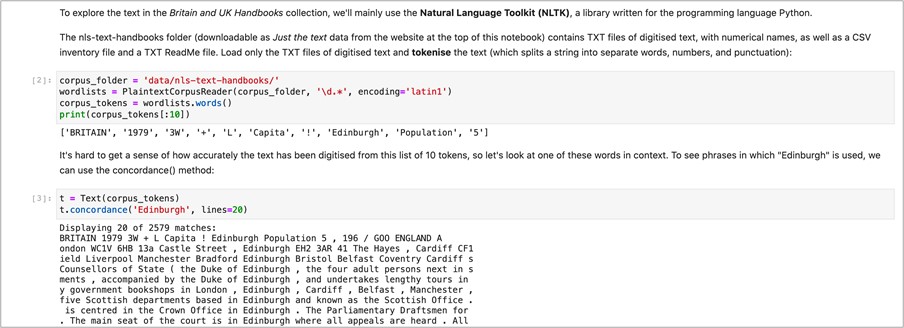
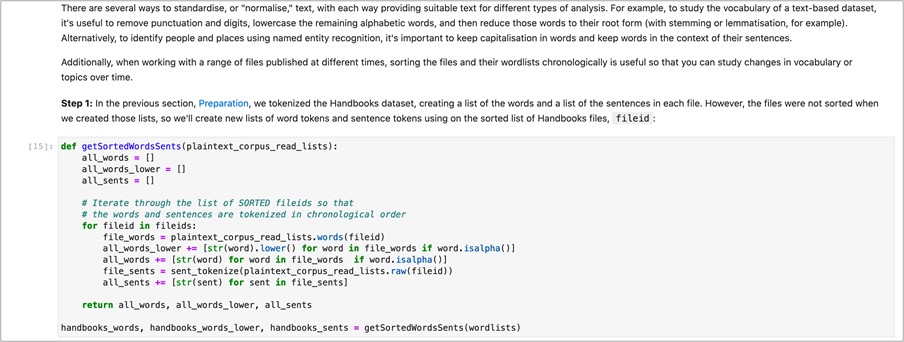
In Data Cleaning and Standardisation, I create several subsets of the data that normalise the text as appropriate for different types of text analysis. For example, to analyse the vocabulary of a dataset (e.g. lexical diversity, word frequencies), all the words of a text source should be lowercased so that “Mining” and “mining” are considered the same word. In computational linguistics, this process is called casefolding.
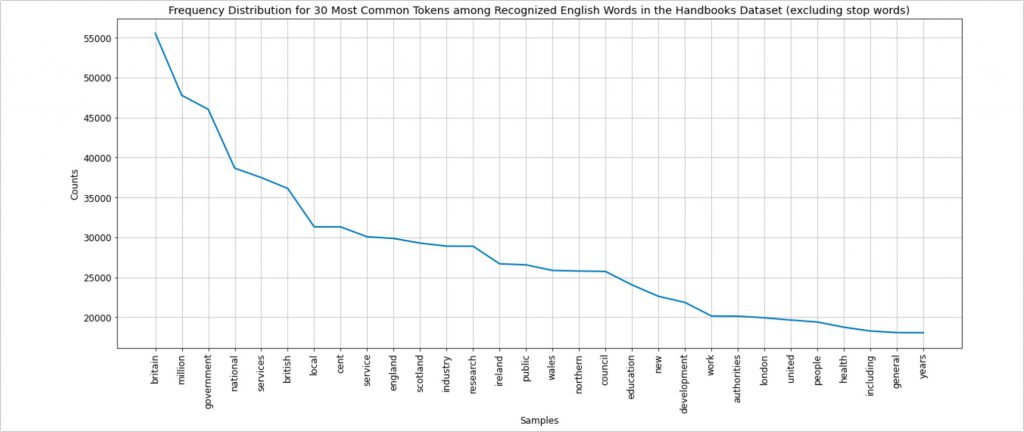
In Summary Statistics, I calculate and visualise the frequency of select words in the Handbooks.
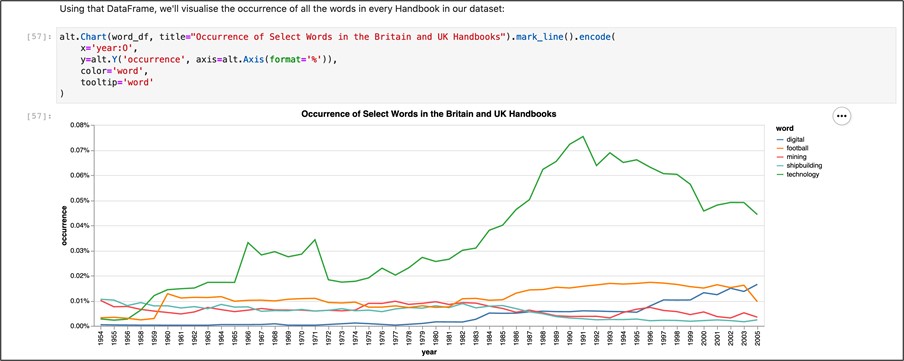
In Exploratory Analysis, I group the Handbooks by the decade in which they were published and compare the occurrences of select words in the Handbooks over time.
Explore the Notebooks
Explore all of the Data Foundry’s Jupyter Notebooks on the Tools page: Jupyter Notebooks