Melissa Terras (Professor of Digital Cultural Heritage, University of Edinburgh) and Dr Rosa Filgueira (Edinburgh Parallel Computing Centre, EPCC) have produced some exploratory analysis of the first eight editions of Encyclopaedia Britannica.
All the world’s knowledge
How has ‘all the world’s knowledge’ been represented over time? What topics have been deemed important to know? How has this changed? And what constitutes ‘knowledge’ in the first place?
Melissa Terras and Rosa Filgueira have been working with datasets on the Data Foundry, developing text mining approaches for use with the collections to form the basis of a new text and data mining platform; one of the collections they have been working with is Encyclopaedia Britannica. Text mining historical text has a number of challenges, including the quality of the data, changes in page layouts, and the size of the dataset. Nearly one hundred years of Encyclopaedia Britannica takes a normal computer a long time to ‘read’!
To produce useful outputs, there are a number of stages the computer must run through, including ‘normalising’ the data (turning letters to lowercase and removing everything that isn’t a letter) and calculating word frequency by taking into account the changing lengths of the different editions.
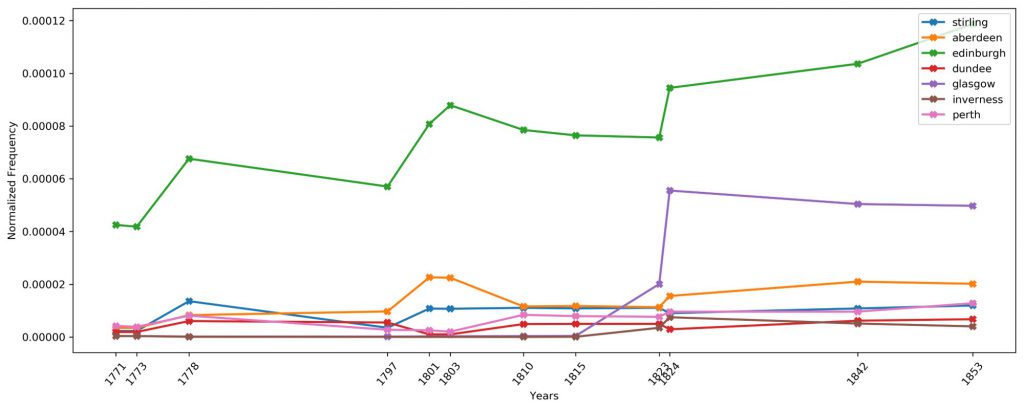
Early work for this project began with n-grams, which provide interesting at-a-glance exploration of the collections. Initial topics searched for, to trial the process, included sports, Scottish philosophers, Scottish cities and animals, showing the changing focus of the Encyclopaedia as more editions were produced.
Identifying articles
Now that this infrastructure is in place, the team can begin to ask more complex questions of data, and work with historians to see how this changes what they can ask of the sources.
Using text mining techniques, the team has extracted ‘articles’ within the Encyclopaedia automatically, bringing the process to do this down to a single command. This means that the topics represented in the Encyclopaedias can now be analysed without the surrounding text.
This will enable new forms of research, encouraging exploration into how many articles each edition of the Encyclopaedia has, and on what topics, enabling the team to look at how these change over time, and how Edinburgh saw – and what it knew of – the world.

The team is now working with Dr Bea Alex and Dr Claire Grover from the Language Technology Group at the University of Edinburgh on how to accurately compute location within each Encyclopaedia entry.
Find out more
This is an ongoing project – more coming soon!
Read more about this work on the EPCC blog: Mining digital historical textual data
Find out more about the Language Technology Group: University of Edinburgh Language Technology Group website
Which dataset did this project use?
This project used Encyclopaedia Britannica: Encylopaedia Britannica dataset on the Data Foundry website