Joe Nockels (PhD student at the University of Edinburgh and University of Glasgow) describes a project to recognise and extract map collection metadata.
Automating laborious data entry
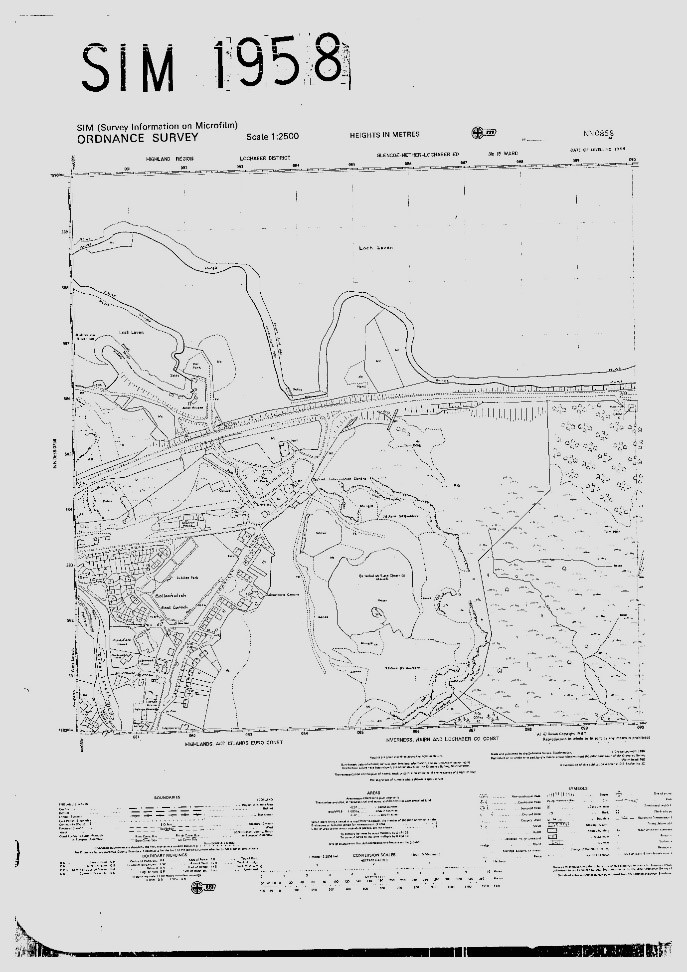
This project aimed to automatically recognise the sheet titles of microfilmed OS maps and print codes from part of the paper map collections. This metadata had not been recorded during the initial scanning of these maps to save time:
1. For the microfilmed OS maps, these had originally been scanned in bulk without any metadata being recorded at all, in the hope that the sheet title metadata could be automatically read from the image in the future using automated methods.
2. For the paper map collections, we did record date metadata relating to revision and publication dates of the maps before scanning. However, the print codes had not been recorded as well, as it was not initially appreciated that this date of printing was also going to be useful in distinguishing multiple states or editions of these maps, especially where the publication date information was not recorded on the maps. As a partial solution, we had used a date of stamping as an approximate date of publication, but this was less useful than the date of printing, which the print codes confirmed.
The wider aims of this project were as follows:
1) Freeing up creative work for the Map Department, injecting the NLS cataloguing process with some automation to make roles less laborious.
2) Highlighting the merit of handwritten text recognition (HTR) technology on NLS collections, away from primarily manuscript content.
3) Experimenting with recognising written features in maps, a largely unsolved problem.
Our process was multi-staged, initially locating relevant metadata to be recognised. The sheet titles, comprising of two letters and four numbers e.g. TT1234, appeared consistently in the upper right of the scanned map image. The print codes appeared in the lower left. This offered us a base to train an AI algorithm to detect this data and extract it from page images.
Training the model using Transkribus
We trained our model using Transkribus, the largest consumer level HTR system, which the NLS has close ties with: being a member of their cooperative structure of individuals and institutions. Using an in-built plugin called P2PaLA, we were able to train the platform in recognising the document structure of these maps – broadly where text regions (TRs) were present and how many the algorithm should recognise.
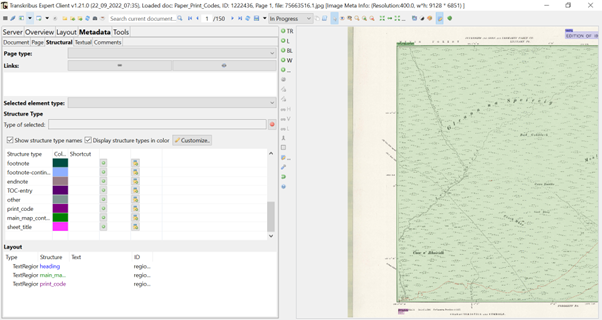
The project began with the uploading of our map files to Transkribus, only after compressing the scans to a maximum file size of 10MB. We then labelled the relevant metadata on our images using structural tags (sometimes called named identities): print_codes, sheet_title, main_map_content. Each of these TRs were labelled using a different colour, customised through the metadata control panel in Transkribus, shown in the below image. This stage was simple, involving the simple dragging and clicking of a box over the information we wanted to extract. We assigned these structural tags over a training set of 50 pages for both collections, providing enough ground truth (GT data) to gain an accurate output.
We then set the parameters for our P2PaLA model, asking it to skip the pages where no tags had been assigned when training and picking random pages to test the quality of its results.
Results
The eventual results from this work were overall positive, producing a trained model using the P2PaLA extension called ‘NLS_Print_Codes’. This model, when applied to the rest of the collection, allowed us to search against key information accurately: for example, ‘print_code’ returned the specific location of all the recognised print_code TRs in the document. A degree of manual cleaning was still needed, as shown in the image below, with Transkribus being over-sensitive and picking up TRs where no text was present. However, these were easily deleted.
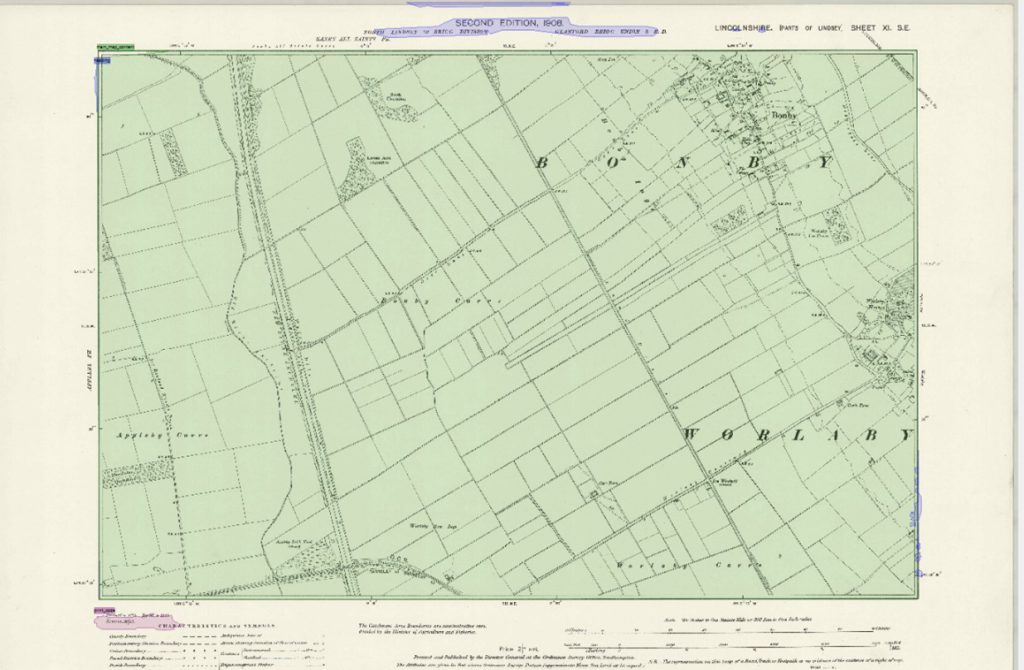
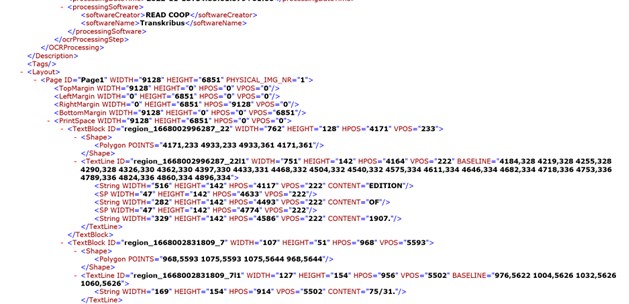
We then applied a pre-trained printed text recognition model, openly licensed on the Transkribus platform, created by the developers, to our material. This model was trained on over 4 million words with a character error rate (CER) of less than 2%. As shown below, the model successfully transcribed the printed codes and sheet titles, although edited the layout structure we had previously trained in many cases.
As such, manual correction – mostly in the form of deleting extraneous text – was needed to clean up these transcriptions, before they could be exported. After this, we were able to export this information in various formats – such as ALTO, providing the coordinates for our metadata needed if these images are to be displayed in interactive viewers online. We were also able to export this information in the form of .csv Excel files.
This data, in line with the principles of the NLS Data Foundry, is made to be easily reusable and should provide a useful resource for the training of other algorithms.
Further work would be needed to train these tools with larger sets of maps to improve accuracy levels. However, these initial results show how promising automated text recognition technology such as Transkribus can be in automatically recording useful map sheet metadata from scanned images, including map titles as well as print code and date information. The models and workflows described here could also easily be adapted to other map series and for automatically recording other metadata.
Find out more
Explore Transkribus: Transkribus website
Visit the Library’s Map Website: NLS Maps website
Which maps were used?
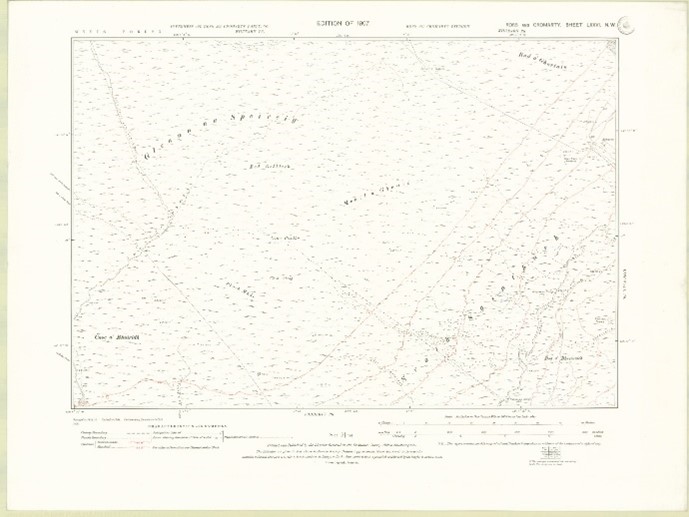
The microfilmed OS map collection dates from ca. 1986-1999 and is in copyright (not available online). Copies can be obtained with OS permission, and the collection will become out-of-copyright within the next 15-25 years, when NLS will put it online.
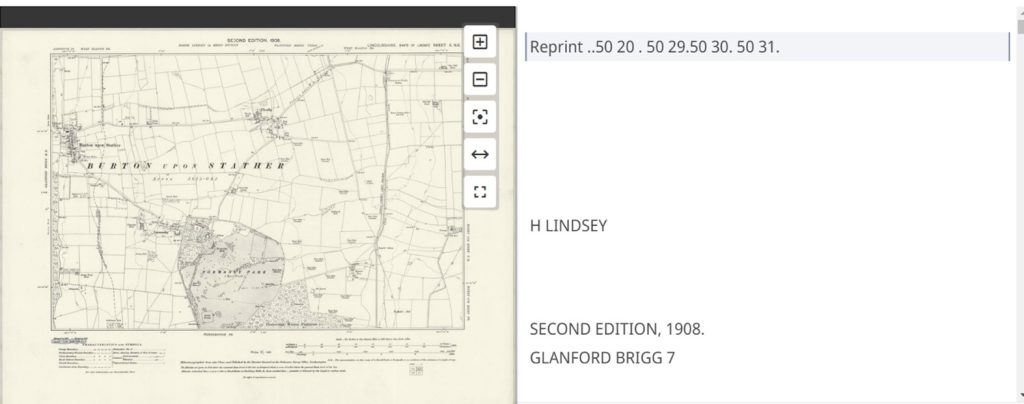
The OS paper map collection used in this project was the OS Six-Inch to the mile (1:10,560) England and Wales series (1840s-1950s) which can be viewed online. You can also view a specific map with a print code ‘75/31’ (confirming that the map was printed in 1931).