These Notebooks have been created by Dr Gustavo Candela, as part of his National Librarian’s Research Fellowship in Digital Scholarship 2022-23 project.
This project explores the adoption of Semantic Web technologies such as Resource Description Framework (RDF), SPARQL and standard vocabularies promoted by relevant institutions to transform, enrich and assess the Data Foundry’s digital collections, which will enable users to understand how the metadata can be improved to enhance discoverability, visibility and reuse.
This work is based on the following metadata datasets including MARCXML as metadata format:
–The National Bibliography of Scotland (version 2)
–Bibliography of Scottish Literature in Translation (BOSLIT)
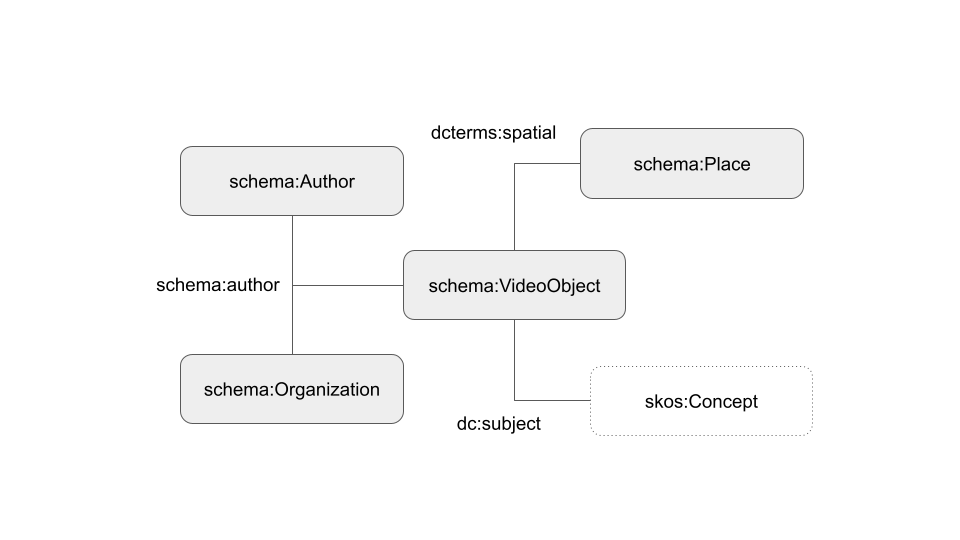
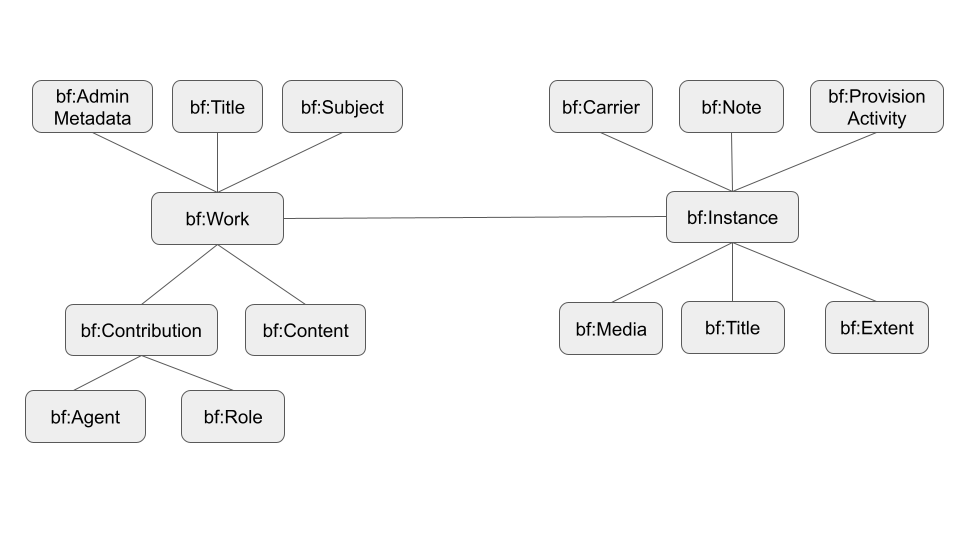
The datasets were enriched with external repositories and assessed by means of different techniques including the use of Shape Expressions, a language for describing RDF graph structures. A collection of ShEx schemas was created to describe and assess the resources stored in the final RDF datasets based on schema.org and BIBFRAME, in particular, for the classes ‘schema:VideoObject’ and ‘bibframe:Work’.
shex:Work
{
rdf:type [bibframe:Work] ;
bibframe:title xsd:string +;
bibframe:hasInstance IRI ?;
bibframe:contribution xsd:string *;
rdf:type [bibframe:Text] ?;
bibframe:adminMetadata xsd:string ?;
bibframe:content IRI ?;
bibframe:language IRI ?;
rdf:type [bibframe:Monograph] ?;
bibframe:subject IRI *;
bibframe:language xsd:string *;
bibframe:note xsd:string *
}
The results of this work are available in the form of a research article (preprint) entitled “Towards a semantic approach in GLAM Labs: the case of the Data Foundry at the National Library of Scotland”. In addition, a GitHub repository was created to include the code and examples developed during the fellowship. An additional code repository was created to be able to load and query large RDF datasets such as the National Bibliography of Scotland.
In addition, this work is based on the principles promoted by the Collections as data initiative and was part of the event Paths to Participation – Collections as Data: State of the Field and Future Directions.

Access the Notebooks
Data extraction from the Moving Image Archive dataset
Open a static version of the Notebooks in your browser:
Download from GitHub to run locally on your machine with Jupyter Lab, Anaconda, or Miniconda:
Exploring the Moving Image Archive dataset as a CSV
Open a static version of the Notebooks in your browser:
Download from GitHub to run locally on your machine with Jupyter Lab, Anaconda, or Miniconda:
Transforming the Moving Image Archive dataset to RDF
Open a static version of the Notebooks in your browser:
Download from GitHub to run locally on your machine with Jupyter Lab, Anaconda, or Miniconda:
Enriching the Moving Image Archive dataset with Wikidata and GeoNames
Open a static version of the Notebooks in your browser:
Download from GitHub to run locally on your machine with Jupyter Lab, Anaconda, or Miniconda:
Data quality assessment of the Moving Image Archive dataset
Open a static version of the Notebooks in your browser:
Download from GitHub to run locally on your machine with Jupyter Lab, Anaconda, or Miniconda:
Exploring the geographic locations in the Moving Image Archive dataset
Open a static version of the Notebooks in your browser:
Download from GitHub to run locally on your machine with Jupyter Lab, Anaconda, or Miniconda:
Exploring the Moving Image Archive dataset
Open a static version of the Notebooks in your browser:
Download from GitHub to run locally on your machine with Jupyter Lab, Anaconda, or Miniconda:
Transformation of the Moving Image Archive
The transformation of the Moving Image Archive dataset was based on schema.org as a main vocabulary. Additional classes and properties from Europeana Data Model (EDM) and Friend of a Friend (FOAF) were used to describe the resources. The metadata was transformed using the RDFLib Python software library.
In addition, the RDF dataset was enriched with external repositories including Wikidata and GeoNames to provide contextual information regarding geographic locations.
The transformation process was described by means of a collection of reproducible Jupyter notebooks. The whole process is described as several steps including the data extraction, transformation, enrichment, exploration and data quality assessment.
Transformation of the National Bibliography of Scotland and BOSLIT
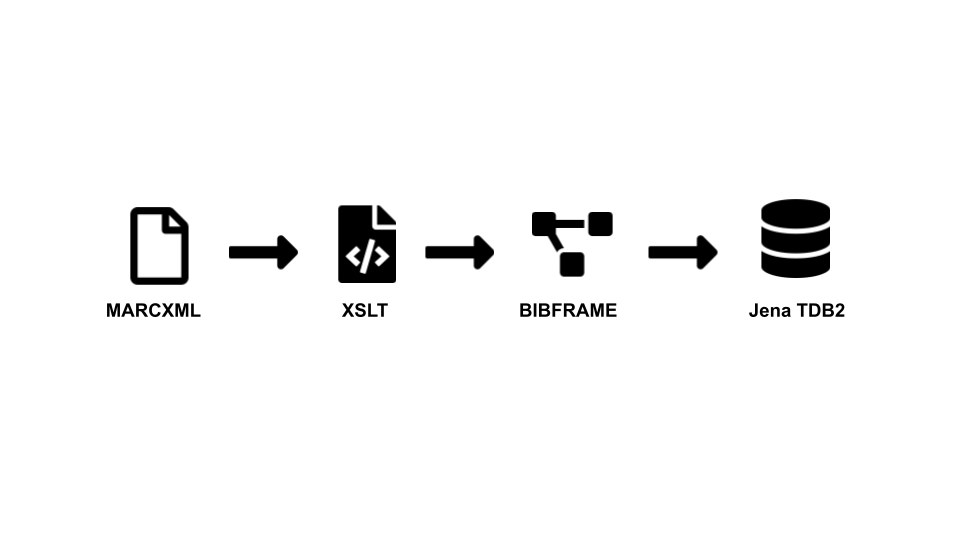
The National Bibliography of Scotland and BOSLIT datasets were transformed to RDF making use of the Bibliographic Framework Initiative (BIBFRAME) as main vocabulary. BIBFRAME is an initiative promoted by the Library of Congress. The transformation was based on the application of the tools provided by the project marc2bibframe2 that is maintained by the Network Development and MARC Standards Office.
Each record provided in the original dataset was extracted using a Python script. The final RDF dataset can be generated and queried using as an RDF storage system the TDB2 Apache Jena component. The code of the project to load and query the RDF data is available as a GitHub repository.
Based on the vocabulary BIBFRAME, a list of SPARQL sentences were created in order to query the RDF datasets. For example, the following example of SPARQL query shows how to query the RDF dataset in order to identify works written by authors containing the label Stevenson, Robert Louis:

Some examples of additional questions that can be answered are:
-Works in a particular language (e.g. Spanish) available at the National Bibliography of Scotland.
-Number of translations per language included in the dataset BOSLIT for a particular work such as Treasure Island and The Strange case of Dr Jekyll and Mr Hyde.
-Number of classes and properties to describe the resources in the dataset.
-Number of works associated with a writer.
Which datasets did this project use?
This project used the following datasets:
–The National Bibliography of Scotland (version 2)
–Bibliography of Scottish Literature in Translation (BOSLIT)