University of Edinburgh honours students supervised by Dr Uta Hinrichs, have used the Catalogue of published material dataset to explore issues of bias and absence.
Visualising the National Library’s catalogue of published collections
Orlagh Keane, School of Informatics, University of Edinburgh
This project aims to explore and provide insights into the vast collection of bibliographic records from the National Library of Scotland’s published material dataset. By visualizing this data, the project aims to enhance accessibility and promote exploration of the rich cultural heritage contained within.
The project offers two main routes into the data: ‘beeswarm’ visualisation, enabling discovery of authors by year, and offering routes via names linking to Wikimedia, the Oxford Dictionary of National Biography, and those names detected to be people, rather than organisations.
It also offers word cloud analysis, by year, of title, description, creator and subject fields.
Visit the project: Visualising the National Library’s catalogue of published collections

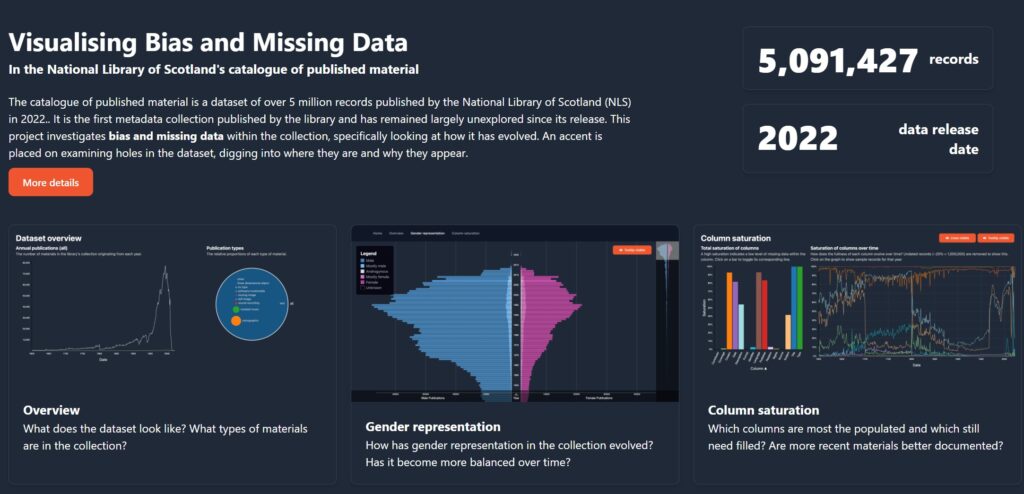
Visualising bias and missing data
Cameron McClymont, School of Informatics, University of Edinburgh
The Catalogue of Published Material is a dataset of over 5 million records published by the National Library of Scotland in 2022. It is the first metadata collection published by the library and has remained largely unexplored since its release. This project investigates bias and missing data within the collection, specifically looking at how it has evolved – and how to visualise these aspects of a dataset in a clear way. The project has a particular focus on examining holes in the dataset, digging into where they are and why they appear.
The visualisations provide a broad overview of the data; an analysis of gender representation in the collections and how this changes over time; and an analysis of metadata fields, and how complete the dataset is.
Visit the project: Visualising bias and missing data
Which dataset did these projects use?
These projects used the Catalogue of published material (version 1) dataset:
Catalogue of published material (version 1) on the Data Foundry website